Method Overview
|
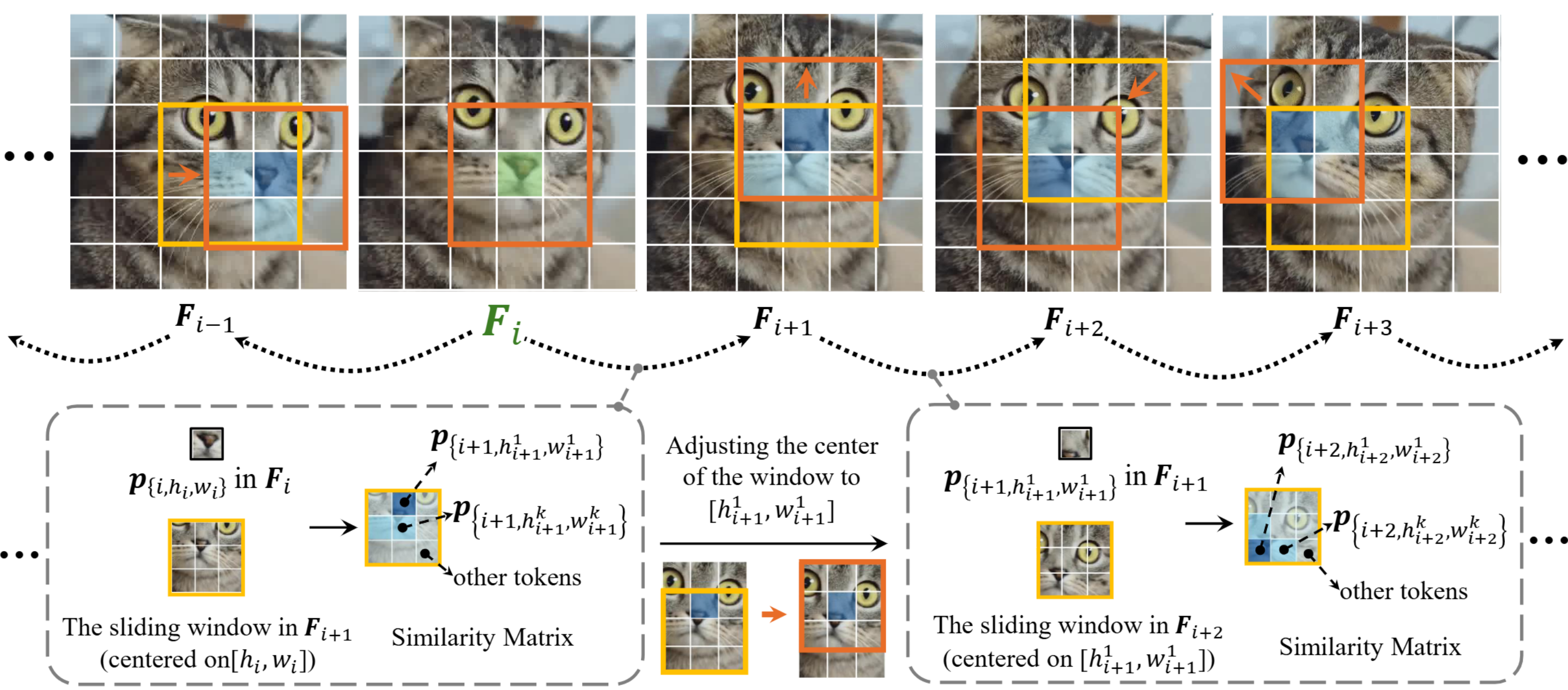
We propose the efficient sliding-window-based strategy for calculating the correspondence relationship among tokens in the diffusion feature of the source video. During the inversion and denoising process, the tokens are sampled based on their correspondence relationship. Through the self-attention among the corresponded tokens across frames, the quality and temporal consistency of edited videos are both significantly enhanced. |
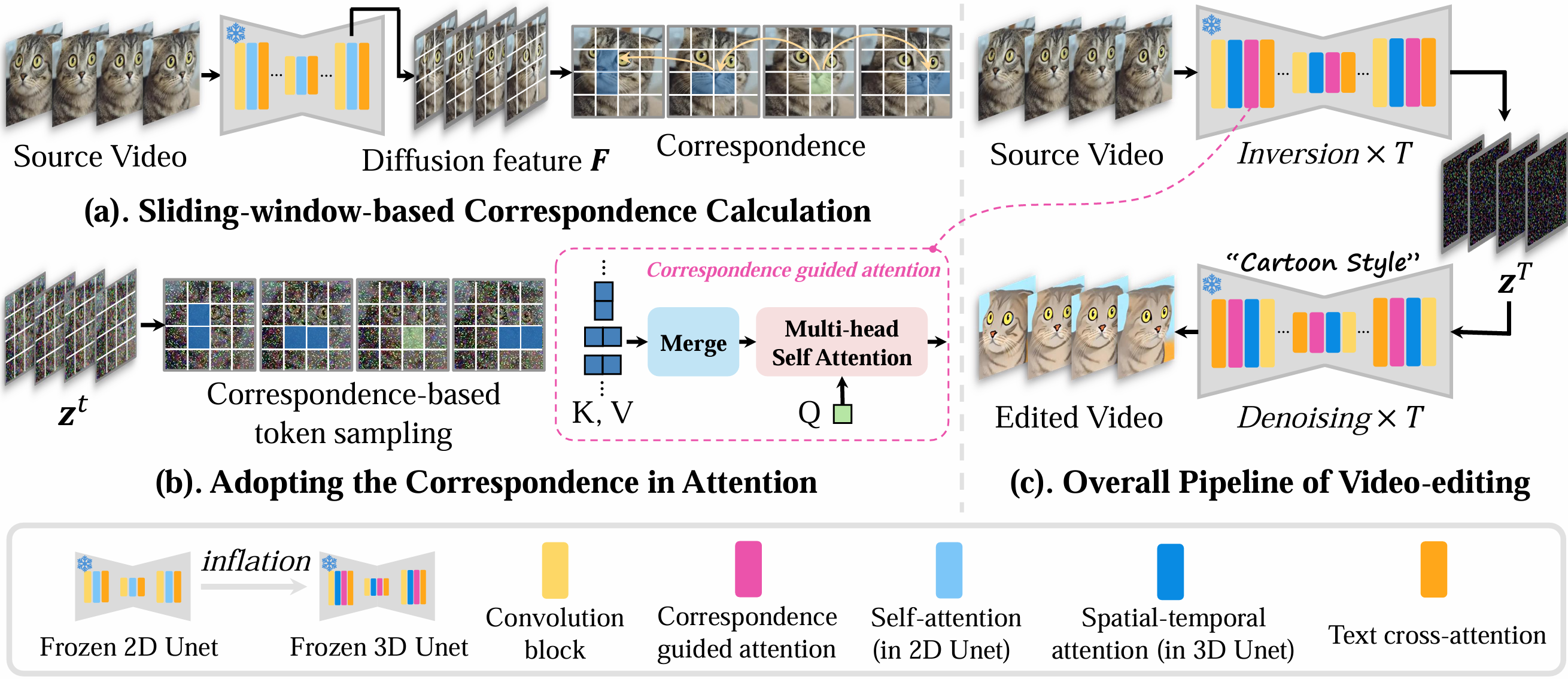
Correspondence Calculation
|
|
Experiment Results
COVE can effectively handle various types of prompts, generating high-quality videos. For both global editing (e.g., style transferring and background editing) and local editing (e.g., modifying the appearance of the subject), COVE demonstrates outstanding performance.
(We are still refining this homepage. More experiment results will be added in the future.)
BibTeX
@article{wang2024cove,
title={COVE: Unleashing the Diffusion Feature Correspondence for Consistent Video Editing},
author={Wang, Jiangshan and Ma, Yue and Guo, Jiayi and Xiao, Yicheng and Huang, Gao and Li, Xiu},
journal={arXiv preprint arXiv:2406.08850},
year={2024}
}